Mediation Analysis#
In the context of causal effect estimation, we aim to evaluate the effect of a specific treatment \(A\) on the outcome \(Y\) of interest. However, there may exist other variables that can be influnced by treamtent, and affect the outcome at the same time. We denote these variables as the Mediators, denoted as \(M\).
Let’s borrow a classical example from [4] to illustrate the necessity of mediation analysis. Researchers would like to evaluate the direct effect of a birth-control pill on the incidence of thrombosis. However, it is also known that the pill has a negative indirect effect on thrombosis by reducing the probability of pregnancy. In this example, we would want to estimate the effect of birth-control pill on thrombosis in the sense that, independent of marital status and other potential mediators that may not be accounted for in the study, in order to obtain reliable and consistent results.
from IPython import display
display.Image("CEL-Mediation-IID.png")
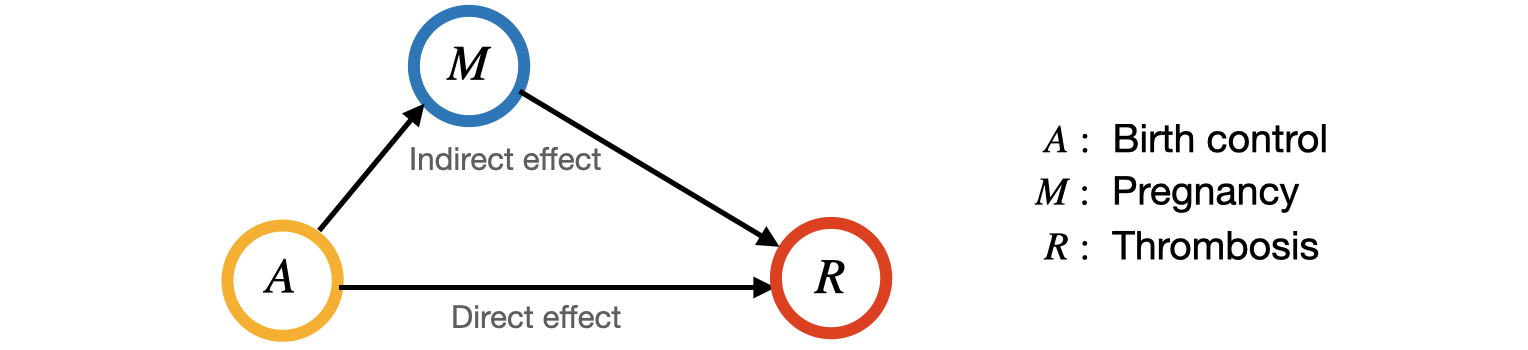
Definitions#
In general mediation analysis, there are two potential paths that can cause the treatment effect on the outcome:
The direct path from treament to outcome, denoted by \(A\rightarrow R\);
The indirect path from treatment to outcome through the mediator \(M\), denoted by \(A\rightarrow M\rightarrow R\).
More specifically, when adjusting the action from \(A=a_0\) to \(A=a_1\), we define the total effect (TE), natural direct effect (DE), and the natural indirect effect (IE) as below:
Under the potential outcome’s structure, we define \(M_a\) as the potential mediator when treatment \(A=a\), and define \(R_{a,m}\) as the potential outcome/reward one would observe under \((A=a, M=m)\). In some literature, the above effects can be samely written as
Identification#
Assumptions:
Consistency: \(M_a = M\) when \(A=a\), and \(R_{a,m}=R\) when \(A=a, M=m\).No unmeasured confounders(i.e.NUC): \(\{R_{a',m},M_a\}\perp A|X\), and \(R_{a',m}\perp M|A=a,X\).Positivity: \(p(m|A,X)>0\) for each \(m\in \mathcal{M}\), and \(p(a|X)>0\) for each \(a\in \mathcal{A}\).
Under the above three assumptions, Imai et al. [3] proved the identifiability of \(\mathbb{E}[R_{1,M_0}]\) and \(\mathbb{E}[R_{a,M_a}]\) in binary action space, which is given by
Estimation#
In this section, we introduce three estimators that are commonly used in mediation analysis when no unmeasured confounders (NUC) assumption holds.
1. Direct Estimator#
The first estimator is the direct method, which is a plug-in estimator based on the identification result above. Since TE, DE and IE can be written as a function of \(\mathbb{E}[R_{a,m_{a'}}]\), it suffice to estimate them separately for any \(a, a'\in \mathcal{A}\) and construct a DM estimator as below:
2. IPW Estimator#
The second estimator in literature is named as the inverse probability weighting estimator, which is similar to the IPW estimator in ATE. Under the existence of mediators, the IPW estimators [2] of DE and IE are given by
where \(\rho(S,A,M)=\frac{p(M|S,A=a_0)}{p(M|S,A)}\) is the probability ratio that can adjust for the bias caused by distribution shift.
3. Multiple Robust (MR) Estimator#
The last estimator is called the multiple robust estimator, which was proposed by Tchetgen and Shpitser [5] based on the efficient influence function in semiparametric theory. The final MR estimator for DE and IE are derived as
Data Demo#
1. AURORA Data#
import pandas as pd
from causaldm.learners.CEL.MA import _env_getdata_AURORA
AURORA_CEL = _env_getdata_AURORA.get_aurora_CEL()
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Input In [2], in <cell line: 2>()
1 import pandas as pd
----> 2 from causaldm.learners.CEL.MA import _env_getdata_AURORA
3 AURORA_CEL = _env_getdata_AURORA.get_aurora_CEL()
ImportError: cannot import name '_env_getdata_AURORA' from 'causaldm.learners.CEL.MA' (D:\anaconda3\lib\site-packages\causaldm\learners\CEL\MA\__init__.py)
AURORA_CEL.columns
Index(['Female', 'Age', 'Non-Hispanic White', 'Education',
'pre-trauma physical health', 'pre-trauma mental health',
'Chronic Perception of Severity of Stress', 'Neuroticism',
'Childhood trauma', 'pre-trauma insomnia (cont)',
'peritraumatic distress', 'W2 acute stress disorder', 'W2 ptsd',
'W2 Depression', '3 month ptsd'],
dtype='object')
import matplotlib.pyplot as plt
plt.hist(AURORA_CEL['pre-trauma insomnia (cont)'],bins=10)
(array([326., 274., 242., 187., 98., 148., 109., 48., 50., 12.]),
array([-8.55287818, -5.75287818, -2.95287818, -0.15287818, 2.64712182,
5.44712182, 8.24712182, 11.04712182, 13.84712182, 16.64712182,
19.44712182]),
<BarContainer object of 10 artists>)
# import related packages
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt;
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.linear_model import LinearRegression
n = len(AURORA_CEL)
state = AURORA_CEL[['Female', 'Age', 'Non-Hispanic White', 'Education',
'pre-trauma physical health', 'pre-trauma mental health',
'Chronic Perception of Severity of Stress', 'Neuroticism',
'Childhood trauma']]
action = AURORA_CEL['pre-trauma insomnia (cont)']
mediator = AURORA_CEL[['peritraumatic distress', 'W2 acute stress disorder', 'W2 ptsd',
'W2 Depression']]
reward = AURORA_CEL['3 month ptsd']
AURORA_CEL_MD = {'state':state,'action':action,'mediator':mediator,'reward':reward}
action[np.where(action>=0)[0]] = 1
action[np.where(action<0)[0]] = 0
/var/folders/9j/vb5nb4rd5bx0gr1q5ytx9q600000gn/T/ipykernel_35787/2568975421.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
action[np.where(action>=0)[0]] = 1
/var/folders/9j/vb5nb4rd5bx0gr1q5ytx9q600000gn/T/ipykernel_35787/2568975421.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
action[np.where(action<0)[0]] = 0
from causaldm.causaldm.learners.Causal_Effect_Learning.Mediation_Analysis.ME_Single import ME_Single
# Control Policy
def control_policy(state = None, dim_state=None, action=None, get_a = False):
if get_a:
action_value = np.array([0])
else:
state = np.copy(state).reshape(-1,dim_state)
NT = state.shape[0]
if action is None:
action_value = np.array([0]*NT)
else:
action = np.copy(action).flatten()
if len(action) == 1 and NT>1:
action = action * np.ones(NT)
action_value = 1-action
return action_value
def target_policy(state, dim_state = 1, action=None):
state = np.copy(state).reshape((-1, dim_state))
NT = state.shape[0]
pa = 1 * np.ones(NT)
if action is None:
if NT == 1:
pa = pa[0]
prob_arr = np.array([1-pa, pa])
action_value = np.random.choice([0, 1], 1, p=prob_arr)
else:
raise ValueError('No random for matrix input')
else:
action = np.copy(action).flatten()
action_value = pa * action + (1-pa) * (1-action)
return action_value
problearner_parameters = {"splitter":["best","random"], "max_depth" : range(1,50)},
Direct_est = ME_Single(AURORA_CEL_MD, r_model = 'OLS',
problearner_parameters = problearner_parameters,
truncate = 50,
target_policy=target_policy, control_policy = control_policy,
dim_state = 9, dim_mediator = 4,
expectation_MCMC_iter = 50,
nature_decomp = True,
seed = 10,
method = 'Direct')
Direct_est.estimate_DE_ME()
Direct_est.est_DE, Direct_est.est_ME, Direct_est.est_TE,
(1.5699712042262648, 1.35390067425173, 2.923871878477995)
IPW_est = ME_Single(AURORA_CEL_MD, r_model = 'OLS',
problearner_parameters = problearner_parameters,
truncate = 50,
target_policy=target_policy, control_policy = control_policy,
dim_state = 9, dim_mediator = 4,
expectation_MCMC_iter = 50,
nature_decomp = True,
seed = 10,
method = 'IPW')
IPW_est.estimate_DE_ME()
IPW_est.est_DE, IPW_est.est_ME, IPW_est.est_TE,
(6.1833766092547435, 1.0830496488123182, 7.266426258067062)
Robust_est = ME_Single(AURORA_CEL_MD, r_model = 'OLS',
problearner_parameters = problearner_parameters,
truncate = 50,
target_policy=target_policy, control_policy = control_policy,
dim_state = 9, dim_mediator = 4,
expectation_MCMC_iter = 50,
nature_decomp = True,
seed = 10,
method = 'Robust')
Robust_est.estimate_DE_ME()
Robust_est.est_DE, Robust_est.est_ME, Robust_est.est_TE,
(1.082810672178048, 2.6367679712306544, 3.7195786434087026)
Robust_DE = np.zeros(5)
Robust_IE = np.zeros(5)
Robust_TE = np.zeros(5)
Robust_DE[0] = Robust_est.est_DE
Robust_IE[0] = Robust_est.est_ME
Robust_TE[0] = Robust_est.est_TE
for i in range(1,5):
mediator_1d = mediator.iloc[:,i-1]
AURORA_CEL_1D = {'state':state,'action':action,'mediator':mediator_1d,'reward':reward}
Robust_est = ME_Single(AURORA_CEL_1D, r_model = 'OLS',
problearner_parameters = problearner_parameters,
truncate = 50,
target_policy=target_policy, control_policy = control_policy,
dim_state = 9, dim_mediator = 1,
expectation_MCMC_iter = 50,
nature_decomp = True,
seed = 10,
method = 'Robust')
Robust_est.estimate_DE_ME()
Robust_DE[i] = Robust_est.est_DE
Robust_IE[i] = Robust_est.est_ME
Robust_TE[i] = Robust_est.est_TE
Mediators_index = ["Overall"]
Mediators_index.append(mediator.columns.values)
print(Mediators_index)
['Overall', array(['peritraumatic distress', 'W2 acute stress disorder', 'W2 ptsd',
'W2 Depression'], dtype=object)]
df = pd.DataFrame()
df['Mediators'] = np.array(['Four mediators in Total','peritraumatic distress', 'W2 acute stress disorder', 'W2 ptsd','W2 Depression'])
df['DE'] = np.round(Robust_DE.reshape(-1, 1), 3)
df['IE'] = np.round(Robust_IE.reshape(-1, 1), 3)
df['TE'] = np.round(Robust_TE.reshape(-1, 1), 3)
df
| Mediators | DE | IE | TE | |
|---|---|---|---|---|
| 0 | Four mediators in Total | 1.083 | 2.637 | 3.720 |
| 1 | peritraumatic distress | 3.262 | 0.234 | 3.496 |
| 2 | W2 acute stress disorder | 1.017 | 2.435 | 3.452 |
| 3 | W2 ptsd | 1.101 | 2.699 | 3.800 |
| 4 | W2 Depression | 2.465 | 0.748 | 3.214 |
treatment effect#
n = len(AURORA_CEL)
#userinfo_index = np.array([3,5,6,7,8,9,10])
SandA = AURORA_CEL[['Female', 'Age', 'Non-Hispanic White', 'Education',
'pre-trauma physical health', 'pre-trauma mental health',
'Chronic Perception of Severity of Stress', 'Neuroticism',
'Childhood trauma','pre-trauma insomnia (cont)']]
SandA
| Female | Age | Non-Hispanic White | Education | pre-trauma physical health | pre-trauma mental health | Chronic Perception of Severity of Stress | Neuroticism | Childhood trauma | pre-trauma insomnia (cont) | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | -10.131861 | 1 | -0.151941 | 5.741954 | 0.476881 | 3.776439 | 7.879518 | -2.062249 | 1.0 |
| 1 | 1 | 13.868139 | 0 | 2.848059 | 6.081954 | 1.706881 | -1.223561 | 6.879518 | 11.937751 | 0.0 |
| 2 | 0 | -11.131861 | 1 | 2.848059 | -2.718046 | -16.393119 | 3.776439 | 14.879518 | 16.937751 | 0.0 |
| 3 | 0 | 15.868139 | 0 | 5.848059 | -28.418046 | -21.323119 | 3.776439 | 13.879518 | 0.937751 | 1.0 |
| 4 | 1 | 22.868139 | 1 | -5.151941 | 0.241954 | -4.483119 | 3.776439 | 8.879518 | -9.062249 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1489 | 1 | -15.131861 | 1 | -2.151941 | 2.641954 | 3.506881 | 1.776439 | -7.120482 | -9.062249 | 0.0 |
| 1490 | 0 | 22.868139 | 0 | 2.848059 | 4.321954 | 4.656881 | -3.223561 | -12.120482 | 13.937751 | 1.0 |
| 1491 | 1 | -4.131861 | 1 | -2.151941 | 7.841954 | 9.146881 | -3.223561 | -13.120482 | -9.062249 | 0.0 |
| 1492 | 0 | -5.131861 | 0 | -2.151941 | 5.231954 | 7.216881 | -0.223561 | 2.879518 | -9.062249 | 0.0 |
| 1493 | 0 | -14.131861 | 1 | -2.151941 | 7.441954 | -2.333119 | 1.776439 | 4.879518 | -9.062249 | 0.0 |
1494 rows × 10 columns
# S-learner
np.random.seed(0)
S_learner = GradientBoostingRegressor(max_depth=5)
S_learner.fit(SandA, reward)
GradientBoostingRegressor(max_depth=5)
SandA_all1 = SandA.copy()
SandA_all0 = SandA.copy()
SandA_all1['pre-trauma insomnia (cont)']=np.ones(n)
SandA_all0['pre-trauma insomnia (cont)']=np.zeros(n)
ATE_DM = np.sum(S_learner.predict(SandA_all1) - S_learner.predict(SandA_all0))/n
ATE_DM
2.3238214724070896
# propensity score model fitting
from sklearn.linear_model import LogisticRegression
ps_model = LogisticRegression()
ps_model.fit(state, action)
LogisticRegression()
pi_S = ps_model.predict_proba(state)
ATE_IS = np.sum((action/pi_S[:,1] - (1-action)/pi_S[:,0])*reward)/n
ATE_IS
3.583008488326464
np.sum(action*(reward-S_learner.predict(SandA_all1))/pi_S[:,1] - (1-action)*(reward-S_learner.predict(SandA_all0))/pi_S[:,0])/n
0.6766993378439592
# combine the DM estimator and IS estimator
ATE_DR = ATE_DM + np.sum(action*(reward-S_learner.predict(SandA_all1))/pi_S[:,1] - (1-action)*(reward-S_learner.predict(SandA_all0))/pi_S[:,0])/n
ATE_DR
3.0005208102510488
# mediation effect
df = pd.DataFrame(columns=['DE','IE','TE'],index=['four mediators in total'])
df.iloc[0,] = [round(Robust_est.est_DE,3), round(Robust_est.est_ME,3), round(Robust_est.est_TE,3)]
df
| DE | IE | TE | |
|---|---|---|---|
| four mediators in total | 1.083 | 2.636768 | 3.719579 |
# treatment effect
df = pd.DataFrame(columns=['DM','IS','DR'],index=['treatment effect'])
df.iloc[0,] = [round(ATE_DM,3), round(ATE_IS,3), round(ATE_DR,3)]
df
| DM | IS | DR | |
|---|---|---|---|
| treatment effect | 2.324 | 3.583 | 3.001 |
2. Covid19 Data#
import os
import pandas as pd
Covid19_CEL = pd.read_csv('./causaldm/data/covid19.csv')
Covid19_CEL
| A | Shenzhen | Guangzhou | Beijing | Chengdu | Shanghai | Dongguan | Suzhou | Xian | Hangzhou | ... | Shangqiu | Yueyang | Zhumadian | Changde | Nanyang | Yichun | Xinyang | Anqing | Jiujiang | Y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 12.292852 | 14.637413 | 11.913318 | 9.513904 | 9.951952 | 10.795226 | 8.010544 | 7.147116 | 7.071851 | ... | 1.266743 | 1.045451 | 1.026626 | 0.794902 | 1.157263 | 1.012273 | 0.940021 | 0.693004 | 0.797915 | 0.500000 |
| 1 | 0 | 11.427091 | 13.792291 | 11.098134 | 9.176879 | 9.740606 | 10.069790 | 8.111048 | 6.927152 | 6.917465 | ... | 1.264442 | 1.065442 | 1.042891 | 0.762210 | 1.123276 | 0.971190 | 0.944849 | 0.717563 | 0.782914 | 1.095238 |
| 2 | 0 | 10.760591 | 13.172900 | 10.868353 | 8.536234 | 9.939283 | 10.098691 | 8.088660 | 6.262078 | 6.735539 | ... | 1.208682 | 0.955573 | 1.069427 | 0.698803 | 1.084979 | 0.902696 | 0.899230 | 0.633096 | 0.769921 | 0.477273 |
| 3 | 0 | 12.454398 | 14.250654 | 11.939562 | 9.149566 | 10.784729 | 11.779052 | 8.719391 | 6.173107 | 7.448533 | ... | 1.226761 | 0.964872 | 1.125997 | 0.729486 | 1.135069 | 0.921326 | 0.925182 | 0.662126 | 0.828047 | 1.400000 |
| 4 | 0 | 15.140390 | 16.108600 | 13.047156 | 9.815548 | 11.533363 | 15.173536 | 9.308488 | 6.199351 | 7.838208 | ... | 1.107659 | 0.944363 | 1.028927 | 0.715424 | 1.018883 | 0.925700 | 0.820400 | 0.639058 | 0.878947 | 0.807692 |
| 5 | 0 | 18.062158 | 17.586850 | 14.469484 | 10.326334 | 13.479242 | 17.650710 | 10.264352 | 6.682694 | 8.736854 | ... | 1.204114 | 1.037254 | 1.075291 | 0.779771 | 1.060582 | 1.021507 | 0.796522 | 0.680173 | 0.951977 | 0.294326 |
| 6 | 0 | 24.530267 | 20.571570 | 17.428835 | 12.473093 | 17.179841 | 21.077723 | 12.149741 | 7.637036 | 10.281233 | ... | 1.204114 | 1.046941 | 1.168571 | 0.811361 | 1.052676 | 0.972389 | 0.864756 | 0.701395 | 0.995490 | 0.109589 |
| 7 | 0 | 25.897320 | 19.382069 | 17.289806 | 13.041032 | 17.683110 | 21.672166 | 13.529203 | 7.909618 | 10.029841 | ... | 1.250219 | 1.108112 | 1.210270 | 0.863557 | 1.155546 | 1.055981 | 1.000739 | 0.749153 | 0.995393 | 0.192593 |
| 8 | 0 | 25.482535 | 19.164017 | 19.656821 | 14.651928 | 18.708246 | 19.588910 | 14.148011 | 8.490420 | 10.440770 | ... | 1.347127 | 1.144951 | 1.270242 | 0.921650 | 1.215292 | 1.102442 | 0.982433 | 0.801220 | 1.037740 | 0.287785 |
| 9 | 0 | 27.171677 | 22.030898 | 23.854759 | 19.128409 | 22.576126 | 18.770616 | 16.191284 | 10.435813 | 12.084196 | ... | 1.605906 | 1.307340 | 1.474589 | 1.099494 | 1.373177 | 1.253232 | 1.124960 | 0.867672 | 1.146863 | 0.136656 |
| 10 | 0 | 21.894203 | 19.635793 | 23.820545 | 20.845285 | 21.278246 | 12.950636 | 14.930212 | 11.173367 | 10.965229 | ... | 1.370520 | 1.184868 | 1.296518 | 1.052125 | 1.178420 | 1.140642 | 1.001873 | 0.828338 | 1.050149 | 0.080622 |
| 11 | 0 | 17.782546 | 17.214282 | 23.914472 | 22.644101 | 19.630285 | 8.992847 | 12.822527 | 12.474421 | 10.188018 | ... | 1.345831 | 1.115597 | 1.228738 | 0.996008 | 1.097064 | 0.981428 | 0.926802 | 0.829375 | 0.990533 | -0.013089 |
| 12 | 1 | 13.192243 | 13.280890 | 18.643705 | 18.702932 | 17.017906 | 6.253913 | 9.882940 | 11.059254 | 7.509737 | ... | 1.164002 | 0.993222 | 0.934286 | 0.946955 | 0.993287 | 0.844765 | 0.716947 | 0.736582 | 0.871981 | -0.112732 |
| 13 | 1 | 5.649070 | 6.621102 | 8.116686 | 9.858802 | 7.429514 | 2.851297 | 4.776376 | 5.181538 | 3.740580 | ... | 0.935064 | 0.719345 | 0.759164 | 0.641585 | 0.651791 | 0.540918 | 0.933250 | 0.507287 | 0.469476 | 0.082212 |
| 14 | 1 | 3.603982 | 4.724633 | 5.303232 | 7.312939 | 4.179535 | 1.980677 | 3.236501 | 3.528457 | 2.656411 | ... | 1.327752 | 1.076134 | 1.299791 | 0.936846 | 1.181952 | 0.839581 | 1.539065 | 0.909695 | 0.693490 | 0.226519 |
| 15 | 1 | 2.528723 | 3.417358 | 3.668425 | 5.043352 | 2.848219 | 1.364526 | 2.062001 | 2.410301 | 1.871230 | ... | 1.475528 | 1.144627 | 1.231135 | 1.126969 | 1.357398 | 0.983761 | 1.193422 | 1.097615 | 0.838285 | -0.171171 |
| 16 | 1 | 1.876705 | 2.463145 | 2.434180 | 3.511868 | 1.921547 | 1.050862 | 1.366664 | 1.753326 | 1.281971 | ... | 1.309997 | 0.980845 | 1.002650 | 1.022058 | 1.032005 | 0.805918 | 1.060452 | 1.125673 | 0.747338 | -0.035326 |
| 17 | 1 | 1.606716 | 1.988680 | 1.813622 | 2.686867 | 1.432760 | 0.928552 | 1.074092 | 1.395144 | 0.947214 | ... | 1.112098 | 0.881150 | 0.896476 | 1.002845 | 0.916207 | 0.701719 | 0.867089 | 0.964613 | 0.667084 | -0.028169 |
| 18 | 1 | 1.524647 | 1.808017 | 1.606230 | 2.339734 | 1.215940 | 0.950746 | 0.921715 | 1.220864 | 0.834689 | ... | 1.039230 | 0.792536 | 0.855976 | 0.924145 | 0.838933 | 0.679882 | 0.776855 | 0.864724 | 0.625158 | -0.194203 |
| 19 | 1 | 1.376806 | 1.638014 | 1.428127 | 1.903468 | 1.053162 | 0.893333 | 0.826913 | 1.059934 | 0.711601 | ... | 0.905191 | 0.597521 | 0.799891 | 0.754369 | 0.733082 | 0.605912 | 0.650462 | 0.715133 | 0.540011 | -0.086331 |
| 20 | 1 | 1.324318 | 1.604902 | 1.240240 | 1.678514 | 0.941771 | 0.853870 | 0.713999 | 0.979322 | 0.616151 | ... | 0.712055 | 0.463547 | 0.557215 | 0.588222 | 0.473332 | 0.490730 | 0.426028 | 0.610805 | 0.424375 | -0.129921 |
| 21 | 1 | 1.425470 | 1.787702 | 1.371460 | 1.939302 | 0.995036 | 0.940572 | 0.799697 | 1.127974 | 0.644533 | ... | 0.808024 | 0.487328 | 0.679655 | 0.636077 | 0.505732 | 0.551934 | 0.427194 | 0.720673 | 0.465912 | -0.119910 |
| 22 | 1 | 1.512886 | 1.614200 | 1.222873 | 1.902820 | 0.931370 | 0.935323 | 0.742122 | 1.076328 | 0.511175 | ... | 0.659210 | 0.398034 | 0.508583 | 0.481010 | 0.334271 | 0.442130 | 0.314993 | 0.574808 | 0.323708 | -0.012853 |
| 23 | 1 | 1.231297 | 1.336565 | 1.064632 | 1.691572 | 0.771898 | 0.755795 | 0.555790 | 0.826524 | 0.377654 | ... | 0.463709 | 0.298825 | 0.384718 | 0.390226 | 0.231304 | 0.293252 | 0.237298 | 0.407236 | 0.208753 | -0.187500 |
| 24 | 1 | 1.095703 | 1.326748 | 0.995069 | 1.561226 | 0.689310 | 0.758128 | 0.536836 | 0.751842 | 0.328633 | ... | 0.442843 | 0.317066 | 0.344704 | 0.432572 | 0.222232 | 0.263768 | 0.236682 | 0.413294 | 0.201139 | -0.134615 |
| 25 | 1 | 1.112065 | 1.308668 | 0.848588 | 1.496653 | 0.631476 | 0.753268 | 0.488916 | 0.658012 | 0.287518 | ... | 0.452855 | 0.368485 | 0.305532 | 0.549990 | 0.226249 | 0.283597 | 0.255247 | 0.420746 | 0.231887 | -0.174074 |
| 26 | 1 | 1.123373 | 1.341781 | 0.936619 | 1.448701 | 0.607144 | 0.780030 | 0.488851 | 0.602057 | 0.247115 | ... | 0.512957 | 0.437562 | 0.307703 | 0.774619 | 0.272419 | 0.290434 | 0.297724 | 0.444755 | 0.256219 | -0.255605 |
| 27 | 1 | 1.095412 | 1.440439 | 1.013504 | 1.414357 | 0.610546 | 0.890255 | 0.512341 | 0.571795 | 0.249934 | ... | 0.600437 | 0.716202 | 0.380214 | 1.153991 | 0.348203 | 0.350406 | 0.359122 | 0.605135 | 0.347911 | -0.289157 |
| 28 | 1 | 1.086858 | 1.482754 | 0.947506 | 1.316801 | 0.626033 | 0.920290 | 0.583686 | 0.558284 | 0.269568 | ... | 0.595220 | 1.123405 | 0.366314 | 1.195333 | 0.334984 | 0.400108 | 0.395086 | 0.606463 | 0.410411 | -0.271186 |
| 29 | 1 | 1.437782 | 1.738454 | 1.033301 | 1.221707 | 0.695304 | 1.084946 | 0.659016 | 0.564570 | 0.292928 | ... | 0.551027 | 0.872629 | 0.374933 | 0.788778 | 0.311137 | 0.351248 | 0.413392 | 0.450814 | 0.372341 | -0.360465 |
| 30 | 1 | 1.015837 | 1.396958 | 0.901724 | 0.952949 | 0.620428 | 0.857758 | 0.526792 | 0.436590 | 0.248962 | ... | 0.437627 | 0.522839 | 0.301417 | 0.502103 | 0.274428 | 0.232308 | 0.308740 | 0.295520 | 0.225860 | -0.090909 |
| 31 | 1 | 0.995587 | 1.330279 | 0.886270 | 0.834527 | 0.656683 | 0.879530 | 0.525366 | 0.432540 | 0.286967 | ... | 0.518789 | 0.455188 | 0.322412 | 0.449485 | 0.348494 | 0.236520 | 0.295650 | 0.286870 | 0.214488 | -0.873563 |
| 32 | 1 | 0.957841 | 1.388632 | 0.875351 | 0.830671 | 0.674438 | 0.940637 | 0.531976 | 0.439182 | 0.316094 | ... | 0.531587 | 0.445144 | 0.340297 | 0.448254 | 0.360742 | 0.249350 | 0.296428 | 0.302875 | 0.213581 | -0.424242 |
| 33 | 1 | 1.025266 | 1.409206 | 0.826394 | 0.816610 | 0.645473 | 1.057374 | 0.544352 | 0.409633 | 0.348300 | ... | 0.458590 | 0.384232 | 0.315997 | 0.400205 | 0.328763 | 0.280001 | 0.247244 | 0.280584 | 0.213905 | -0.052632 |
| 34 | 1 | 0.847292 | 1.199707 | 0.807311 | 0.791759 | 0.614239 | 0.896800 | 0.520700 | 0.434322 | 0.364986 | ... | 0.516326 | 0.421654 | 0.294775 | 0.432475 | 0.319950 | 0.318913 | 0.210438 | 0.269082 | 0.239209 | 0.000000 |
| 35 | 1 | 1.419055 | 1.741241 | 0.908431 | 0.955282 | 0.779803 | 1.225012 | 0.722066 | 0.528898 | 0.528379 | ... | 0.663617 | 0.538099 | 0.322801 | 0.482760 | 0.354683 | 0.398066 | 0.240667 | 0.335632 | 0.288036 | -0.444444 |
| 36 | 1 | 1.159110 | 1.644332 | 0.912514 | 1.006085 | 0.814860 | 1.225400 | 0.734929 | 0.505570 | 0.716072 | ... | 0.881734 | 0.582487 | 0.436298 | 0.607565 | 0.509652 | 0.551902 | 0.411350 | 0.418997 | 0.459529 | -0.645161 |
| 37 | 1 | 1.304294 | 1.796126 | 0.914522 | 1.095768 | 0.906228 | 1.343434 | 0.856688 | 0.531166 | 0.808380 | ... | 0.997596 | 0.624607 | 0.522742 | 0.600113 | 0.597650 | 0.659275 | 0.439182 | 0.439279 | 0.510786 | -0.363636 |
38 rows × 32 columns
# import related packages
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt;
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.linear_model import LinearRegression
n = len(Covid19_CEL)
38
state = np.zeros(n).reshape(-1, 1)
#state = np.array(Covid19_CEL['Beijing']).reshape(-1, 1)
action = np.array(Covid19_CEL['A'])
mediator = np.array(Covid19_CEL['Y'])
reward = np.array(Covid19_CEL['Tianjin'])
MovieLens_CEL_MD = {'state':state,'action':action,'mediator':mediator,'reward':reward}
from causaldm.causaldm.learners.Causal_Effect_Learning.Mediation_Analysis.ME_Single import ME_Single
# Control Policy
def control_policy(state = None, dim_state=None, action=None, get_a = False):
if get_a:
action_value = np.array([0])
else:
state = np.copy(state).reshape(-1,dim_state)
NT = state.shape[0]
if action is None:
action_value = np.array([0]*NT)
else:
action = np.copy(action).flatten()
if len(action) == 1 and NT>1:
action = action * np.ones(NT)
action_value = 1-action
return action_value
def target_policy(state, dim_state = 1, action=None):
state = np.copy(state).reshape((-1, dim_state))
NT = state.shape[0]
pa = 1 * np.ones(NT)
if action is None:
if NT == 1:
pa = pa[0]
prob_arr = np.array([1-pa, pa])
action_value = np.random.choice([0, 1], 1, p=prob_arr)
else:
raise ValueError('No random for matrix input')
else:
action = np.copy(action).flatten()
action_value = pa * action + (1-pa) * (1-action)
return action_value
problearner_parameters = {"splitter":["best","random"], "max_depth" : range(1,50)},
Direct_est = ME_Single(MovieLens_CEL_MD, r_model = 'OLS',
problearner_parameters = problearner_parameters,
truncate = 50,
target_policy=target_policy, control_policy = control_policy,
dim_state = 1, dim_mediator = 1,
expectation_MCMC_iter = 50,
nature_decomp = True,
seed = 10,
method = 'Direct')
Direct_est.estimate_DE_ME()
Direct_est.est_DE, Direct_est.est_ME, Direct_est.est_TE,
(-4.730690894257576, 0.13369489173373478, -4.5969960025238406)
IPW_est = ME_Single(MovieLens_CEL_MD, r_model = 'OLS',
problearner_parameters = problearner_parameters,
truncate = 50,
target_policy=target_policy, control_policy = control_policy,
dim_state = 1, dim_mediator = 1,
expectation_MCMC_iter = 50,
nature_decomp = True,
seed = 10,
method = 'IPW')
IPW_est.estimate_DE_ME()
IPW_est.est_DE, IPW_est.est_ME, IPW_est.est_TE,
(-5.143298762540704, 0.5474864933099358, -4.595812269230768)
Robust_est = ME_Single(MovieLens_CEL_MD, r_model = 'OLS',
problearner_parameters = problearner_parameters,
truncate = 50,
target_policy=target_policy, control_policy = control_policy,
dim_state = 1, dim_mediator = 1,
expectation_MCMC_iter = 50,
nature_decomp = True,
seed = 10,
method = 'Robust')
Robust_est.estimate_DE_ME()
Robust_est.est_DE, Robust_est.est_ME, Robust_est.est_TE,
(-4.592741884817156, -0.001726777600432909, -4.594468662417588)
Robust_DE = np.zeros(30)
Robust_IE = np.zeros(30)
Robust_TE = np.zeros(30)
for i in range(1,31):
state = np.zeros(n).reshape(-1, 1)
#state = np.array(Covid19_CEL['Beijing']).reshape(-1, 1)
action = np.array(Covid19_CEL['A'])
mediator = np.array(Covid19_CEL['Y'])
reward = np.array(Covid19_CEL.iloc[:,i])
MovieLens_CEL_MD = {'state':state,'action':action,'mediator':mediator,'reward':reward}
MovieLens_CEL_MD
Robust_est = ME_Single(MovieLens_CEL_MD, r_model = 'OLS',
problearner_parameters = problearner_parameters,
truncate = 50,
target_policy=target_policy, control_policy = control_policy,
dim_state = 1, dim_mediator = 1,
expectation_MCMC_iter = 50,
nature_decomp = True,
seed = 10,
method = 'Robust')
Robust_est.estimate_DE_ME()
Robust_DE[i-1] = Robust_est.est_DE
Robust_IE[i-1] = Robust_est.est_ME
Robust_TE[i-1] = Robust_est.est_TE
# Analysis of causal effects of 2020 Hubei lockdowns on reducing the COVID-19 spread in China regulated by Chinese major cities outside Hubei
df = pd.DataFrame()
df['cities'] = np.array(Covid19_CEL.columns.values[1:31])
df['DE'] = np.round(Robust_DE.reshape(-1, 1), 3)
df['IE'] = np.round(Robust_IE.reshape(-1, 1), 3)
df['TE'] = np.round(Robust_TE.reshape(-1, 1), 3)
df
| cities | DE | IE | TE | |
|---|---|---|---|---|
| 0 | Shenzhen | -19.438 | 2.918 | -16.521 |
| 1 | Guangzhou | -15.709 | 0.842 | -14.867 |
| 2 | Beijing | -16.170 | 1.922 | -14.248 |
| 3 | Chengdu | -11.453 | 1.053 | -10.400 |
| 4 | Shanghai | -15.216 | 1.969 | -13.247 |
| 5 | Dongguan | -14.952 | 1.367 | -13.586 |
| 6 | Suzhou | -11.025 | 1.037 | -9.989 |
| 7 | Xian | -6.854 | 0.235 | -6.619 |
| 8 | Hangzhou | -8.516 | 0.500 | -8.016 |
| 9 | Zhengzhou | -8.311 | 0.924 | -7.387 |
| 10 | Chongqing | -3.731 | -0.081 | -3.812 |
| 11 | Changsha | -6.421 | 0.679 | -5.742 |
| 12 | Nanjing | -5.251 | 0.134 | -5.117 |
| 13 | Kunming | -4.399 | 0.136 | -4.263 |
| 14 | Tianjin | -4.593 | -0.002 | -4.594 |
| 15 | Hefei | -3.771 | 0.163 | -3.608 |
| 16 | Nanning | -3.629 | 0.323 | -3.306 |
| 17 | Wenzhou | -2.717 | -1.192 | -3.909 |
| 18 | Nanchang | -2.197 | 0.056 | -2.141 |
| 19 | Zhoukou | -0.416 | -0.153 | -0.570 |
| 20 | Fuyang | -0.485 | -0.058 | -0.543 |
| 21 | Shangqiu | -0.408 | -0.104 | -0.512 |
| 22 | Yueyang | -0.404 | -0.032 | -0.437 |
| 23 | Zhumadian | -0.444 | -0.154 | -0.598 |
| 24 | Changde | -0.165 | 0.016 | -0.149 |
| 25 | Nanyang | -0.440 | -0.158 | -0.598 |
| 26 | Yichun | -0.473 | -0.062 | -0.536 |
| 27 | Xinyang | -0.176 | -0.241 | -0.416 |
| 28 | Anqing | -0.062 | -0.103 | -0.165 |
| 29 | Jiujiang | -0.493 | -0.017 | -0.510 |
References#
Hicks, Raymond and Dustin Tingley (2011). “Causal mediation analysis”. In: The Stata Journal 11.4, pp. 605–619.
Hong, Guanglei et al. (2010). “Ratio of mediator probability weighting for estimating natural direct and indirect effects”. In: Proceedings of the American Statistical Association, biometrics section. Alexandria, VA, USA, pp. 2401–2415.
Imai, Kosuke, Luke Keele, and Dustin Tingley (2010). “A general approach to causal mediation analysis.”. In: Psychological methods 15.4, p. 309.
Pearl, Judea (2022). “Direct and indirect effects”. In: Probabilistic and causal inference: The works of Judea Pearl, pp. 373–392.
Tchetgen, Eric J Tchetgen and Ilya Shpitser (2012). “Semiparametric theory for causal mediation analysis: efficiency bounds, multiple robustness, and sensitivity analysis”. In: Annals of statistics 40.3, p. 1816.