Ooline Policy Learning in Non-Markovian Environments#
An important extension of the Markov assumption-based RL is to the non-Markovian environment. We provide a brief introduction in this chapter.
Model#
Recall the model we introduce in online RL with MDP.
In comparison, we essentially cannot assume the MA and CMIA conditions any longer, and hence need to use all historical information in decision making.
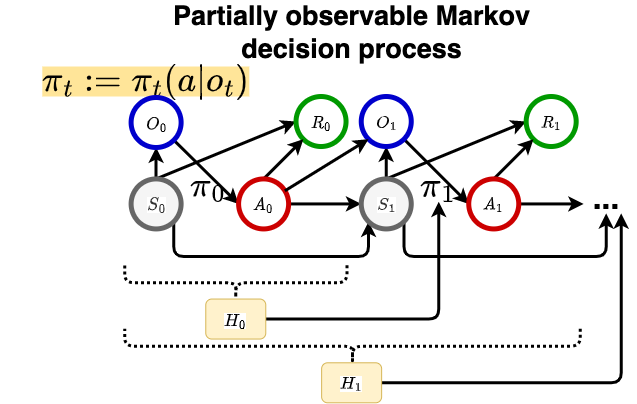
We make the comparison in POMDP_comparison.
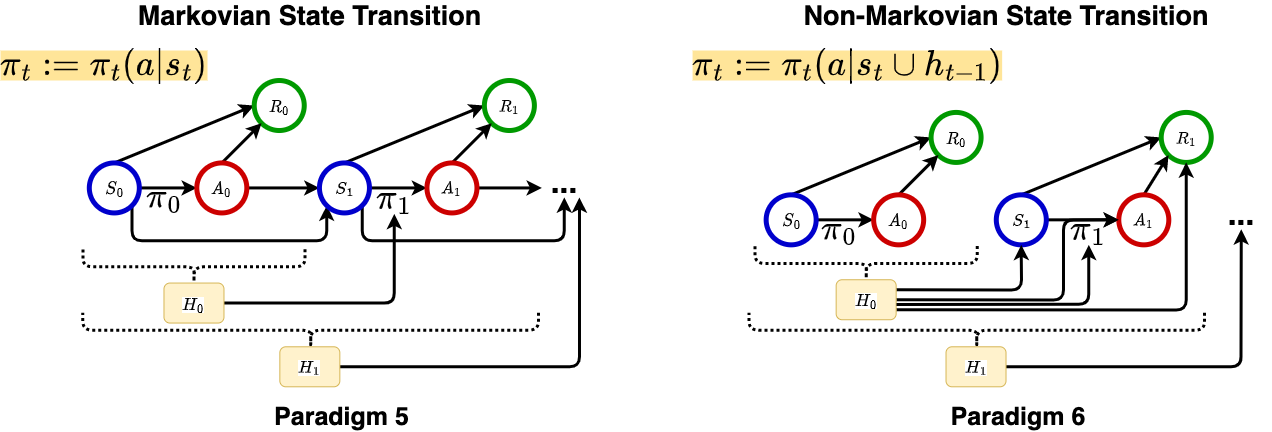
The extension is valuable when either (i) the system dynamic depends on multiple or infinite lagged time points and hence it is infeasible to summarize historical information in a fixed-dimensional vector (the DTR problem that we studied in Paradigm 2), or when (ii) the underlying model is an MDP yet the state is not observable, which corresponds to the well-known Partially observable Markov decision process (POMDP).
Note that the model of POMDP is actually slightly different, which we summarize in POMDP.
Fortunately, unlike in the offline setting [SZY+22], in the online setup, even with unobservable variables, there would be no causal bias, since the action selection does not depend on unmeasured variables.
Policy learning#
It is challenging to learn the optimal policy in a POMDP due to the model complexity. Below, we mainly introduce three classes of approaches.
When the horizon is short (e.g., 2 or 3), it is still feasible to learn a time-dependent policy that directly utilizes the vector of all historical information for decision making. This is the online version of the DTR problem and was recently studied in Hu and Kallus [HK20]. However, when the horiozn is longer, such an approach quickly becomes computationally infeasible and certain dimension reduction method is then needed.
In POMDP, a classic approach is to infer the underlying state via the history information, and then use the inferred state distribution as a belief state for decision making [Spa12].
In recent years, there is also a growing literature on applying memory-based NN architecture for directly learning the policy from a sequence of history transition tuples [MGKulic21, ZLPM17].
References#
Yichun Hu and Nathan Kallus. Dtr bandit: learning to make response-adaptive decisions with low regret. arXiv preprint arXiv:2005.02791, 2020.
Lingheng Meng, Rob Gorbet, and Dana Kulić. Memory-based deep reinforcement learning for pomdps. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 5619–5626. IEEE, 2021.
Chengchun Shi, Jin Zhu, Shen Ye, Shikai Luo, Hongtu Zhu, and Rui Song. Off-policy confidence interval estimation with confounded markov decision process. Journal of the American Statistical Association, pages 1–12, 2022.
Matthijs TJ Spaan. Partially observable markov decision processes. Reinforcement learning: State-of-the-art, pages 387–414, 2012.
Pengfei Zhu, Xin Li, Pascal Poupart, and Guanghui Miao. On improving deep reinforcement learning for pomdps. arXiv preprint arXiv:1704.07978, 2017.